PixelFlow allows you to use all these features
Unlock the full potential of generative AI with Segmind. Create stunning visuals and innovative designs with total creative control. Take advantage of powerful development tools to automate processes and models, elevating your creative workflow.
Segmented Creation Workflow
Gain greater control by dividing the creative process into distinct steps, refining each phase.
Customized Output
Customize at various stages, from initial generation to final adjustments, ensuring tailored creative outputs.
Layering Different Models
Integrate and utilize multiple models simultaneously, producing complex and polished creative results.
Workflow APIs
Deploy Pixelflows as APIs quickly, without server setup, ensuring scalability and efficiency.
Gemini 2.0 Flash
Gemini 2.0 Flash features native image generation capabilities, allowing users to generate and edit images through natural language prompts. Its key strength is the ability to generate multimodal outputs, creating relevant images alongside text within a single model.
Key Features
-
Native Image Output: Generates images directly in conjunction with text, simplifying the development process for visually rich applications.
-
Consistent Multimodal Storytelling: Can illustrate stories from textual prompts, maintaining consistent characters and settings across generated images.
-
Interactive Conversational Image Editing: Supports multi-turn natural language dialogue for image editing, allowing for iterative refinement and exploration of visual ideas while retaining context.
-
World-Aware Realistic Imagery: Utilizes world knowledge and enhanced reasoning to produce accurate and detailed images suitable for realistic depictions like recipe illustrations.
-
Strong Text Rendering in Images: Demonstrates superior ability to accurately render long sequences of text in images compared to other models, making it suitable for creating legible advertisements and social media content.
-
Single Model for Text and Image: Integrates both text and image generation capabilities into one model, offering a unified approach to multimodal content creation.
Use Cases
-
Visually Engaging Storybooks (Entertainment/Education): Enables the creation of illustrated narratives with consistent visuals based on text input.
-
Collaborative Ad Design (Marketing): Facilitates iterative refinement of marketing visuals through natural language feedback and editing.
-
Illustrated Recipe Guides (Food Industry/Publishing): Generates detailed and accurate images to accompany recipe instructions, enhancing user experience.
-
Dynamic Social Media Posts (Social Media Management): Produces visually appealing social media content with accurately rendered text for effective communication and engagement.
-
Visually Enhanced AI Assistants (Software Development): Allows AI agents to generate visual responses and create interactive, illustrated experiences within applications
Gemini 2.0 Flash presents a powerful experimental platform for developers seeking to integrate native text and image generation into their applications. Its unique features, such as conversational image editing and robust text rendering, combined with its multimodal capabilities, offer significant potential for creating engaging and visually rich user experiences.
Other Popular Models
sdxl-img2img
SDXL Img2Img is used for text-guided image-to-image translation. This model uses the weights from Stable Diffusion to generate new images from an input image using StableDiffusionImg2ImgPipeline from diffusers

sadtalker
Audio-based Lip Synchronization for Talking Head Video
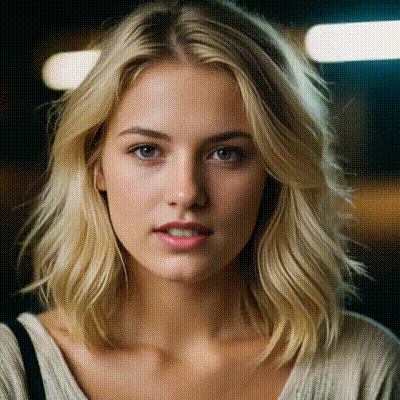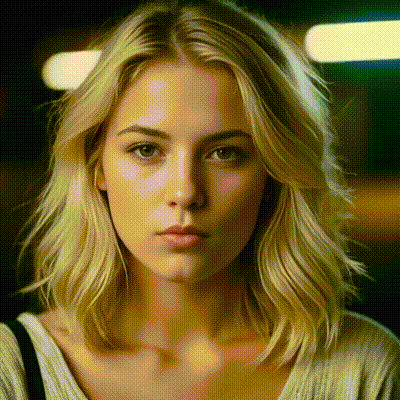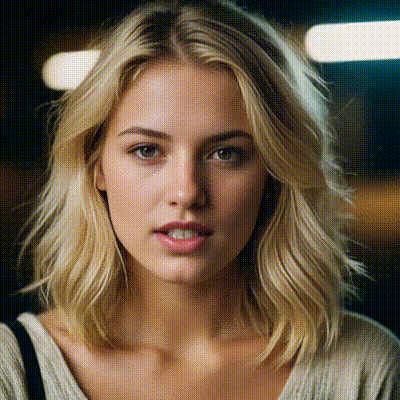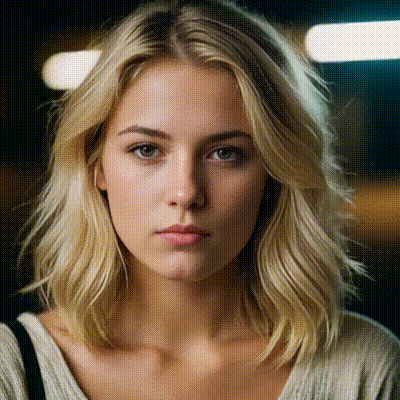
sdxl-inpaint
This model is capable of generating photo-realistic images given any text input, with the extra capability of inpainting the pictures by using a mask

sd1.5-epicrealism
This model corresponds to the Stable Diffusion Epic Realism checkpoint for detailed images at the cost of a super detailed prompt
