
PixelFlow allows you to use all these features
Unlock the full potential of generative AI with Segmind. Create stunning visuals and innovative designs with total creative control. Take advantage of powerful development tools to automate processes and models, elevating your creative workflow.
Segmented Creation Workflow
Gain greater control by dividing the creative process into distinct steps, refining each phase.
Customized Output
Customize at various stages, from initial generation to final adjustments, ensuring tailored creative outputs.
Layering Different Models
Integrate and utilize multiple models simultaneously, producing complex and polished creative results.
Workflow APIs
Deploy Pixelflows as APIs quickly, without server setup, ensuring scalability and efficiency.
Samaritan Lightning SDXL
The Samaritan Lightning SDXL model revolutionizes image generation by specializing in producing niji midjourney 3D style cartoon images that enchant viewers with their unique and captivating visual storytelling. This cutting-edge model is meticulously engineered to deliver high-quality and creatively styled cartoon images that stand out in the realm of digital artistry.
A standout feature of the Samaritan Lightning SDXL is its exceptional ability to swiftly and efficiently generate high-quality cartoon images in the distinctive niji midjourney 3D style, making it a preferred choice for applications that seek to infuse their visual content with a touch of artistic flair and storytelling. With the capacity to produce captivating and immersive 3D cartoon images that resonate with creativity, this model offers a unique blend of speed and artistic innovation.
To optimize the performance of the Samaritan Lightning SDXL, ensuring compatibility with the DPM++ SDE Karras / DPM++ SDE sampler is essential. Leveraging 4-6 sampling steps and a CFG Scale set between 1 and 2 is recommended to achieve peak performance and efficiency in the image generation process. These tailored settings are crucial for unlocking the full creative potential of this advanced model and producing cartoon images that embody the essence of niji midjourney artistry.
Other Popular Models
sdxl-img2img
SDXL Img2Img is used for text-guided image-to-image translation. This model uses the weights from Stable Diffusion to generate new images from an input image using StableDiffusionImg2ImgPipeline from diffusers

sadtalker
Audio-based Lip Synchronization for Talking Head Video
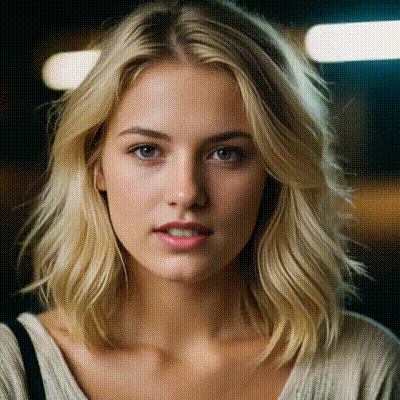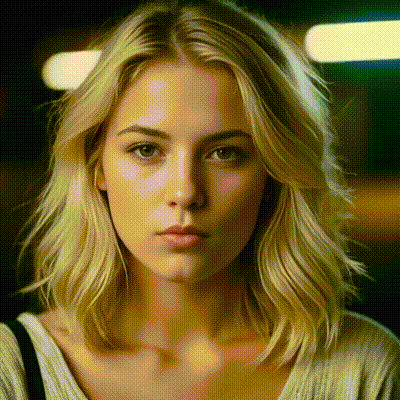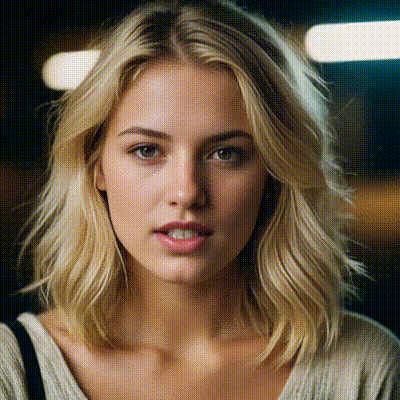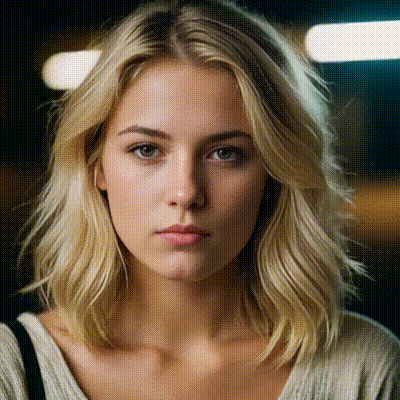
instantid
InstantID aims to generate customized images with various poses or styles from only a single reference ID image while ensuring high fidelity

sd2.1-faceswapper
Take a picture/gif and replace the face in it with a face of your choice. You only need one image of the desired face. No dataset, no training
