API
If you're looking for an API, you can choose from your desired programming language.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
import requests
api_key = "YOUR_API_KEY"
url = "https://api.segmind.com/v1/kolors"
# Prepare data and files
data = {}
files = {}
data['cfg'] = 6
data['seed'] = 441234134
data['steps'] = 25
data['width'] = 1024
data['height'] = 1024
data['prompt'] = "In this lively 2D illustration, three animated boys joyfully have their laughter filling the air. , adding warmth and charm. The agave field behind them radiates warmth, emphasizing the authenticity of this gathering spot and the togetherness of the boys sharing a moment of joy."
data['scheduler'] = "EulerDiscreteScheduler"
data['output_format'] = "webp"
data['output_quality'] = 80
data['negative_prompt'] = ""
data['number_of_images'] = 1
headers = {'x-api-key': api_key}
# If no files, send as JSON
if files:
response = requests.post(url, data=data, files=files, headers=headers)
else:
response = requests.post(url, json=data, headers=headers)
print(response.content) # The response is the generated imageAttributes
Guidance scale
min : 0,
max : 20
Set a seed for reproducibility. Random by default.
Number of inference steps
min : 1,
max : 50
Width of the image
min : 512,
max : 2048
Height of the image
min : 512,
max : 2048
An enumeration.
Allowed values:
An enumeration.
Allowed values:
Quality of the output images, from 0 to 100. 100 is best quality, 0 is lowest quality.
min : 0,
max : 100
Things you do not want to see in your image
Number of images to generate
min : 1,
max : 10
To keep track of your credit usage, you can inspect the response headers of each API call. The x-remaining-credits property will indicate the number of remaining credits in your account. Ensure you monitor this value to avoid any disruptions in your API usage.
Kolors
Kolors, developed by the Kuaishou Kolors team, is a remarkable text-to-image generation model that operates at the intersection of language and visual art. Trained on an extensive dataset comprising billions of text-image pairs, Kolors stands out for its impressive visual quality, nuanced semantic accuracy, and adept text rendering capabilities—both in Chinese and English.
Key Features of Kolors
-
Latent Diffusion-Based Architecture: It leverages latent diffusion, a powerful technique that allows it to transform textual descriptions into vivid, photorealistic images. This architecture ensures that the generated visuals capture the essence of the input text while maintaining realism.
-
Bilingual Competence: It can seamlessly handles both Chinese and English inputs. Its understanding of context and ability to generate content in both languages make it a versatile tool for creators worldwide.
-
Visual Fidelity: Unlike many open-source models, it doesn’t compromise on visual fidelity. Its images exhibit fine details, rich textures, and coherent compositions, making them suitable for a wide range of applications—from digital art to e-commerce.
-
Semantic Precision: When tasked with generating images based on textual prompts, it excels at capturing complex semantics. Whether it’s a serene landscape or a whimsical creature, the model interprets the nuances of the input text with finesse.
Technical Details
-
Inference Steps: Kolors performs inference in a series of steps. The number of steps influences the trade-off between quality and speed. By default, it uses 25 steps, but this can be adjusted based on specific requirements.
-
Guidance Scale (cfg): This parameter controls the influence of the latent guidance during image synthesis. A higher value results in more faithful representations of the input text.
-
Output Format: Kolors generates images in the WebP format by default, balancing quality and file size. You can also change it to JPEG or PNG in the settings.
Use Cases
-
Artistic Creations: Artists, designers, and content creators can harness Kolors to bring their textual ideas to life. Whether you’re illustrating a fantasy novel cover or designing a captivating social media post, this model provides a canvas for your imagination.
-
E-Commerce and Advertising: Product descriptions often fall flat without compelling visuals. Kolors bridges this gap by generating product images directly from textual descriptions, enhancing the shopping experience for users.
-
Storytelling and Comics: Writers can visualize scenes from their narratives, and comic creators can rapidly prototype panels using Kolors. The model’s ability to evoke imagery from mere words opens up exciting storytelling possibilities.
Other Popular Models
sdxl-controlnet
SDXL ControlNet gives unprecedented control over text-to-image generation. SDXL ControlNet models Introduces the concept of conditioning inputs, which provide additional information to guide the image generation process

sadtalker
Audio-based Lip Synchronization for Talking Head Video
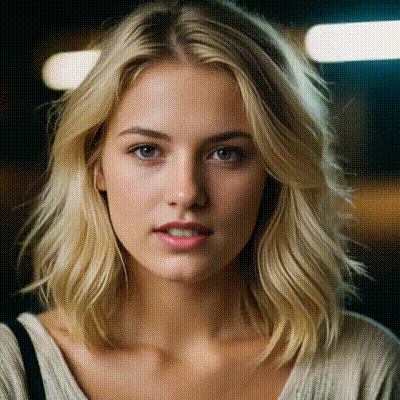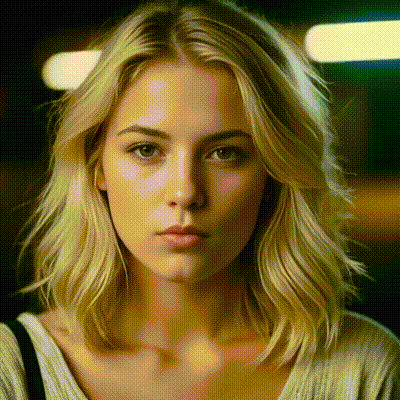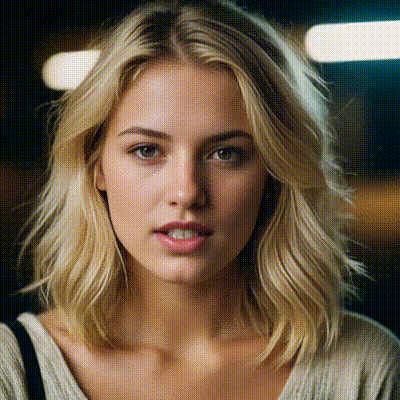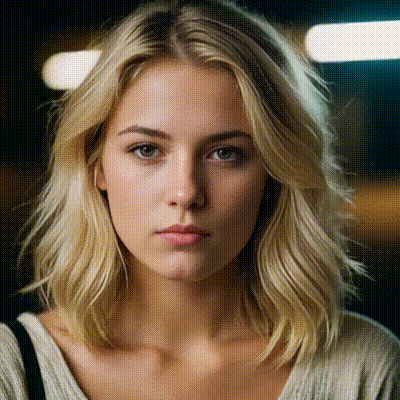
illusion-diffusion-hq
Monster Labs QrCode ControlNet on top of SD Realistic Vision v5.1

faceswap-v2
Take a picture/gif and replace the face in it with a face of your choice. You only need one image of the desired face. No dataset, no training
